newer stuff
Some recent projects that I've worked on...
*For a more frequently updated list of projects, see [my Github repo here](https://github.com/mundyreimer).
---
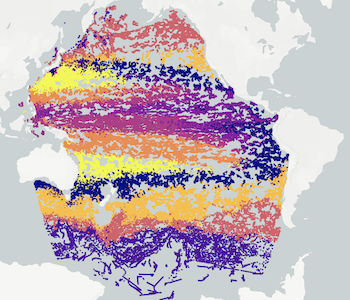 ## Oceanography
[Project Argo](https://github.com/mundyreimer/argo_sensor_clustering): Built various machine learning models such as spectral clustering, k-means, & gaussian mixture models ran on PySpark's distributed computing framework to cluster temperature profiles of the fleet of [Argo floating buoys](https://en.wikipedia.org/wiki/Argo_(oceanography)) around the world. This network of floats monitors temperature, salinity, currents, and bio-optical properties of the world's oceans, providing sensor measurements for climate and oceanographic research. [Data set found here](http://www.argo.ucsd.edu/Argo_data_and.html). Our team's initial project [slide-deck found here](https://docs.google.com/presentation/d/1yQh4USQ-taN2zQ36ukN4ExVCNp2EwumFjSiDIEPRv0s/edit?usp=sharing).
Used: PySpark, AWS EMR, Spectral Clustering, K-Means, Gaussian-Mixture Models, PCA
---
## Music & Linguistics
[Experimented with different machine learning classifiers](https://github.com/mundyreimer/iambic_songs) for determining iambic pentameter in song lyrics and sonnets. Iambic Pentameter is a type of rhythm or meter in which five small groups of syllables called *Iambs* or "feet", which in English are unstressed followed by stressed syllables, are found coupled together. Poem and sonnet data were obtained and cleaned from a variety of sources like Shakespeare, Keats, Frost, Shelley, and Jackson -scraped texts available on the web, while songs from artists such as Taylor Swift and the Backstreet Boys were obtained from [Data.World](https://data.world/).
Used:
---
## Charity
[Designed a recommendation system](https://github.com/mundyreimer/school_donations_project) in conjunction with PySpark's Distributed Computing framework that matches classroom charity projects (teachers and their classroom requests) to the most probable donors nationwide. [DonorChoose.org](https://www.donorschoose.org/about) in partnership with Google helped provide this [data set](https://www.kaggle.com/donorschoose/io) freely available on Kaggle. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1FJU4YzjeObEk91HBzrgQ4pBWyNjErIMun06r4PqKwWI/edit?usp=sharing).
Used:
---
## Dark Web Markets
[Dark Market Cocaine Price Prediction](https://github.com/mundyreimer/dark_market_ml): Used various machine learning models to predict the bitcoin price of dark market cocaine. The [data set](https://www.kaggle.com/everling/cocaine-listings) was scraped by a third party and contains approximately 1,400 standardized product listings from Dream Market's *Cocaine* category. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1adchsYpdnYrKG_umUR0ZynxtBRWPtUcGAgySLA2iRbA/edit?usp=sharing).
Used:
## Oceanography
[Project Argo](https://github.com/mundyreimer/argo_sensor_clustering): Built various machine learning models such as spectral clustering, k-means, & gaussian mixture models ran on PySpark's distributed computing framework to cluster temperature profiles of the fleet of [Argo floating buoys](https://en.wikipedia.org/wiki/Argo_(oceanography)) around the world. This network of floats monitors temperature, salinity, currents, and bio-optical properties of the world's oceans, providing sensor measurements for climate and oceanographic research. [Data set found here](http://www.argo.ucsd.edu/Argo_data_and.html). Our team's initial project [slide-deck found here](https://docs.google.com/presentation/d/1yQh4USQ-taN2zQ36ukN4ExVCNp2EwumFjSiDIEPRv0s/edit?usp=sharing).
Used: PySpark, AWS EMR, Spectral Clustering, K-Means, Gaussian-Mixture Models, PCA
---
## Music & Linguistics
[Experimented with different machine learning classifiers](https://github.com/mundyreimer/iambic_songs) for determining iambic pentameter in song lyrics and sonnets. Iambic Pentameter is a type of rhythm or meter in which five small groups of syllables called *Iambs* or "feet", which in English are unstressed followed by stressed syllables, are found coupled together. Poem and sonnet data were obtained and cleaned from a variety of sources like Shakespeare, Keats, Frost, Shelley, and Jackson -scraped texts available on the web, while songs from artists such as Taylor Swift and the Backstreet Boys were obtained from [Data.World](https://data.world/).
Used:
---
## Charity
[Designed a recommendation system](https://github.com/mundyreimer/school_donations_project) in conjunction with PySpark's Distributed Computing framework that matches classroom charity projects (teachers and their classroom requests) to the most probable donors nationwide. [DonorChoose.org](https://www.donorschoose.org/about) in partnership with Google helped provide this [data set](https://www.kaggle.com/donorschoose/io) freely available on Kaggle. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1FJU4YzjeObEk91HBzrgQ4pBWyNjErIMun06r4PqKwWI/edit?usp=sharing).
Used:
---
## Dark Web Markets
[Dark Market Cocaine Price Prediction](https://github.com/mundyreimer/dark_market_ml): Used various machine learning models to predict the bitcoin price of dark market cocaine. The [data set](https://www.kaggle.com/everling/cocaine-listings) was scraped by a third party and contains approximately 1,400 standardized product listings from Dream Market's *Cocaine* category. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1adchsYpdnYrKG_umUR0ZynxtBRWPtUcGAgySLA2iRbA/edit?usp=sharing).
Used:
## Oceanography
[Project Argo](https://github.com/mundyreimer/argo_sensor_clustering): Built various machine learning models such as spectral clustering, k-means, & gaussian mixture models ran on PySpark's distributed computing framework to cluster temperature profiles of the fleet of [Argo floating buoys](https://en.wikipedia.org/wiki/Argo_(oceanography)) around the world. This network of floats monitors temperature, salinity, currents, and bio-optical properties of the world's oceans, providing sensor measurements for climate and oceanographic research. [Data set found here](http://www.argo.ucsd.edu/Argo_data_and.html). Our team's initial project [slide-deck found here](https://docs.google.com/presentation/d/1yQh4USQ-taN2zQ36ukN4ExVCNp2EwumFjSiDIEPRv0s/edit?usp=sharing).
Used: PySpark, AWS EMR, Spectral Clustering, K-Means, Gaussian-Mixture Models, PCA
---
## Music & Linguistics
[Experimented with different machine learning classifiers](https://github.com/mundyreimer/iambic_songs) for determining iambic pentameter in song lyrics and sonnets. Iambic Pentameter is a type of rhythm or meter in which five small groups of syllables called *Iambs* or "feet", which in English are unstressed followed by stressed syllables, are found coupled together. Poem and sonnet data were obtained and cleaned from a variety of sources like Shakespeare, Keats, Frost, Shelley, and Jackson -scraped texts available on the web, while songs from artists such as Taylor Swift and the Backstreet Boys were obtained from [Data.World](https://data.world/).
Used:
---
## Charity
[Designed a recommendation system](https://github.com/mundyreimer/school_donations_project) in conjunction with PySpark's Distributed Computing framework that matches classroom charity projects (teachers and their classroom requests) to the most probable donors nationwide. [DonorChoose.org](https://www.donorschoose.org/about) in partnership with Google helped provide this [data set](https://www.kaggle.com/donorschoose/io) freely available on Kaggle. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1FJU4YzjeObEk91HBzrgQ4pBWyNjErIMun06r4PqKwWI/edit?usp=sharing).
Used:
---
## Dark Web Markets
[Dark Market Cocaine Price Prediction](https://github.com/mundyreimer/dark_market_ml): Used various machine learning models to predict the bitcoin price of dark market cocaine. The [data set](https://www.kaggle.com/everling/cocaine-listings) was scraped by a third party and contains approximately 1,400 standardized product listings from Dream Market's *Cocaine* category. Our team's [project slide-deck can be found here](https://docs.google.com/presentation/d/1adchsYpdnYrKG_umUR0ZynxtBRWPtUcGAgySLA2iRbA/edit?usp=sharing).
Used: